Build an OpenAI person-like QA bot
After we export WeChat data as text files, we can extract specific person's chat records and build a QA bot that helps answer the questions we have based on this person's history chat logs.
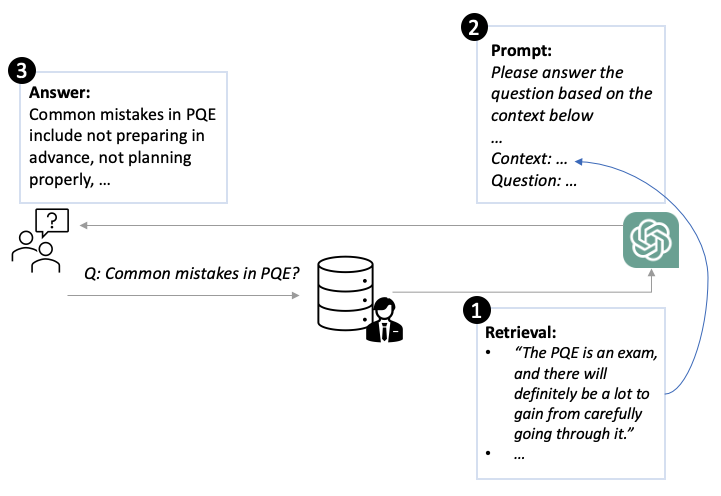
The general idea is that given a user question, we can first retrieve relevant interested person's data from the chat logs. Then, these logs serve as context. And we design a specific prompt that instructs the model to answer the user's question based on the provided history logs.
Parse WeChat chat records
We can use regular expressions to extract interested person's chat records. Specifically, noticing that time stamps (YYYY-MM-DD hh:mm:ss) comes behind the name tags, thus we can \(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\):(.*) to extract people's content. Then, we can use interested person's name tags to filter out his/her contents.
Build QA bot
Given a user's chat logs and a question, we need to first embed them into vectors and then measure their cosine similairties with the question vector. Only chat logs with higher similarity scores will be used to generate answers in the following step. Here, I would recommend sentenceBert (opens new window) to generate sentence/phrase vectors.
Then, we can build a prompt for our OpenAI QA bot (i.e., text-davinci-003 (opens new window)). Specifically, we can use the following strucutre:
Answer the question based on the context below, and if the question can't be answered based on the context, say \"I don't know\"
Context: {context}
Question: {question}
Answer:
Finally, we can get the answers for the user question using GPT 3.5. Some results are presented as follows.
- Question: "PQE常犯的错误?"
Output: 'PQE常犯的错误是讲了很多可视化,每一个可视化都在讲,用户可以做这个,做那个,但都没有故事,下面听众听完就忘。'
- Question: "What are the common mistakes in PQE?"
Output: 'Common mistakes in PQE include not preparing in advance, not planning properly, not having a systematic approach, not having a coherent framework to connect different works, and not having a high-level philosophy or methodology to guide the presentation.'
It seems that GPT 3.5 has better capabilities in undestanding and summarizing in English rather than in Chinese.