What is DeHumor?
Despite being a critical communication skill, grasping humor is challenging—a successful use of humor requires a mixture of both engaging content build-up and an appropriate vocal delivery (e.g., pause). Prior studies on computational humor emphasize the textual and audio features immediately next to the punchline, yet overlooking longer-term context setup. Moreover, the theories are usually too abstract for understanding each concrete humor snippet.
To fill in the gap, we develop DeHumor, a visual analytical system for analyzing humorous behaviors in public speaking. To intuitively reveal the building blocks of each concrete example, DeHumor decomposes each humorous video into multimodal features and provides inline annotations of them on the video script. In particular, to better capture the build-ups, we introduce content repetition as a complement to features introduced in theories of computational humor and visualize them in a context linking graph. To help users locate the punchlines that have the desired features to learn, we summarize the content (with keywords) and humor feature statistics on an augmented time matrix.
Humor feature analysis
Language features and glyphs. We compute and encode three types of semantic features at the sentence level: incongruity, sentiment, and phonetics.
Incongruity. Contrasting incongruous concepts is classic for achieving the comic effect. The semantic incongruity of a sentence can be modeled by the repetition and disconnection, or the relative semantic similarities between word pairs.

Sentiment. Expressing strong sentiment using polarized expressions (how emotionally positive and negative) and subjective statements (how personal) enables a speaker to empathize with the audience.

Phonetics. The most common techniques for phonetics include (1) alliteration chains, which denote multiple words that begin with the same phones, and (2) rhyme chains, which include words ending with the same syllables.

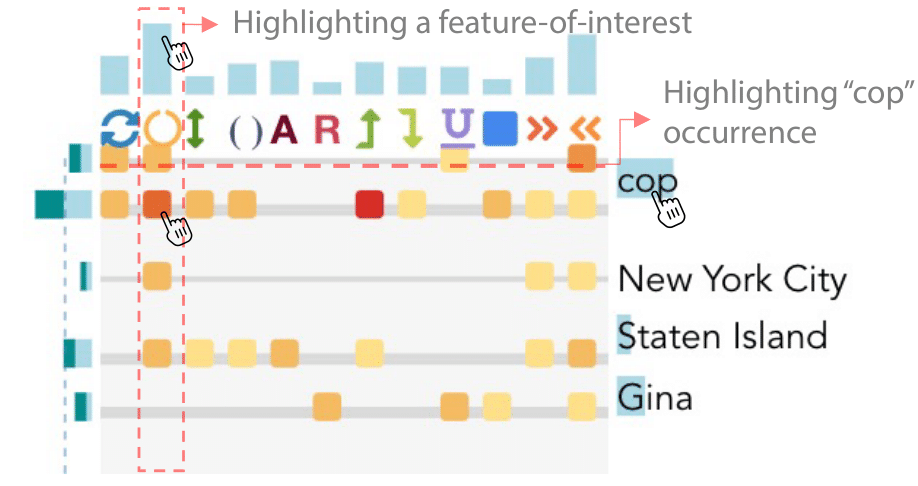
Audio features and glyphs. We extract and encode the following four representative audio features at the sentence level, including speed, pause (), volume ("": louder, "": softer), and pitch (), which reveal the speaker’s vocal delivery style.

Context-level inter-sentence repetition. To reveal the relationship among build-ups of a punchline, we extract and link similar concepts in the punchline context. A speaker would more frequently repeat useful concepts to help prepare the audience for the upcoming punchline. In the example below, the core takeaway of the punchline is that Germany does not have fantastic food. The message becomes clear because of several repetitions in preceding lines. First, the speaker emphasizes his/her focus on the two countries by repeating ("the Italian community", "Their people", "Italy") and ("Germany") in several places. Second, in Lines #3 and #5, the different modifiers "a"" and "no" before the repeated "stigma for (being) evil" highlights the opposite reputations of Germany and Italy after WWII, and therefore builds a natural comparison between the two. The comparison is then carried on to the punchline, implying the German food is the opposite of Italian's.

Augmented time matrix. Besides sentence- and context-level, we design an augmented time matrix that provides an overview of distribution of humor occurrences and multimodal features of speech content and vocal delivery at the speech level.
The barcode chart of the time matrix shows the humor distribution. Besides, we organize the humor features, including the word usage, vocal delivery, and key concepts, around the matrix to summarize their distribution for each punchline and across different punchlines.
DeHumor features
Check out the following video for a quick look at DeHumor's features.
- Introduction to humor in public speaking (0:00 - 0:14)
- Designs of DeHumor (0:14 - 1:29)
- A case study (1:29 - 3:33)
Conclusion
In this work, we presented DeHumor, a visual analytics system for exploring and analyzing humorous snippets in public speaking. The system features multi-level exploration of multimodal humor features with an augmented time matrix and context linking graphs.
In future work, we can improve the system usability by supporting humor query and humor style comparison. We plan to integrate more contextual features (e.g., riddles) and features from other modalities (e.g., facial expressions) into the system. We can also apply deep learning models to improve the feature extraction accuracy. Furthermore, we will conduct a long-term study with more experts to further evaluate the system usability and its effectiveness for humor analysis.
Authors







Xingbo Wang, Yao Ming, Tongshuang Wu, Haipeng Zeng, Yong Wang and Huamin Qu.
IEEE Transactions on Visualization and Computer Graphics. 2021.
- 🌐 Project Page: https://andy-xingbowang.com/dehumor
- 📃 Paper: https://andy-xingbowang.com/papers/dehumor_tvcg.pdf
- 🎥 Video: https://youtu.be/xmpJPSIXmSw
- 💻 System (and data): coming soon