What is CommonsenseVIS?
Commonsense knowledge describes the general facts and beliefs about the world that are obvious and intuitive to most humans. Generally, the commonsense knowledge is represented as graphs, where nodes denote the conceptual entities (e.g., cars, people) and links describe the relations between different concepts (e.g., people "is capable of" driving cars). This knowledge allows people to smoothly explore and reason over everyday events and situations. Equipping machines with human-like commonsense reasoning abilities can greatly benefit the development of social robots and intelligent personal agents, assisting humans in daily tasks.
Recent advances in large pre-trained language models (PLMs) NLP (e.g., BERT, GPT, and T5) have yielded impressive and even human-level performance on commonsense benchmarks. However, these models lack interpretability and transparency, which hinders model debugging and development for real-world applications. It is unclear that
- What commonsense knowledge the models have learned and used in the process of reasoning?
- whether they merely explore the spurious correlation in the datasets?
Challenges
Since the commonsense knowledge is not explicitly stated in the model input and output, many explainability techniques like feature attributions (e.g., Lime and SHAP) cannot be directly applied to reveal models' relational reasoning over concepts (e.g., entities) in different contexts. For example, in "take an umbrella when it rains", the inherent commonsense is that the umbrella "is used for" protection from the rain, which is not mentioned in the original statement. Moreover, contexts significantly influence the reasoning over these implicit relations between concepts. For instance, depending on the weather, the umbrella can "be used for" protection from the rain or sun.
Given the complexity and vastness of the commonsense knowledge space the models operate on, where concepts are intertwined with various relations and contexts, it is challenging to scale up these methods to efficiently build high-level abstractions of model behavior (e.g., under what contexts a relation is well learned) and generalize model understanding to large datasets.
Our solution
CommonsenseVIS is a visual explanatory system designed to enable NLP experts to conduct a systematic and scalable analysis of the commonsense reasoning capabilities of NLP models. It utilizes external commonsense knowledge bases (i.e., ConceptNet in our case) to contextualize the behavior of models, especially in commonsense question-answering scenarios that involves a large number of concepts and their relations. By extracting relevant commonsense knowledge from inputs as references, it aligns model behavior with human knowledge through multi-level visualizations and interactive model probing and editing.
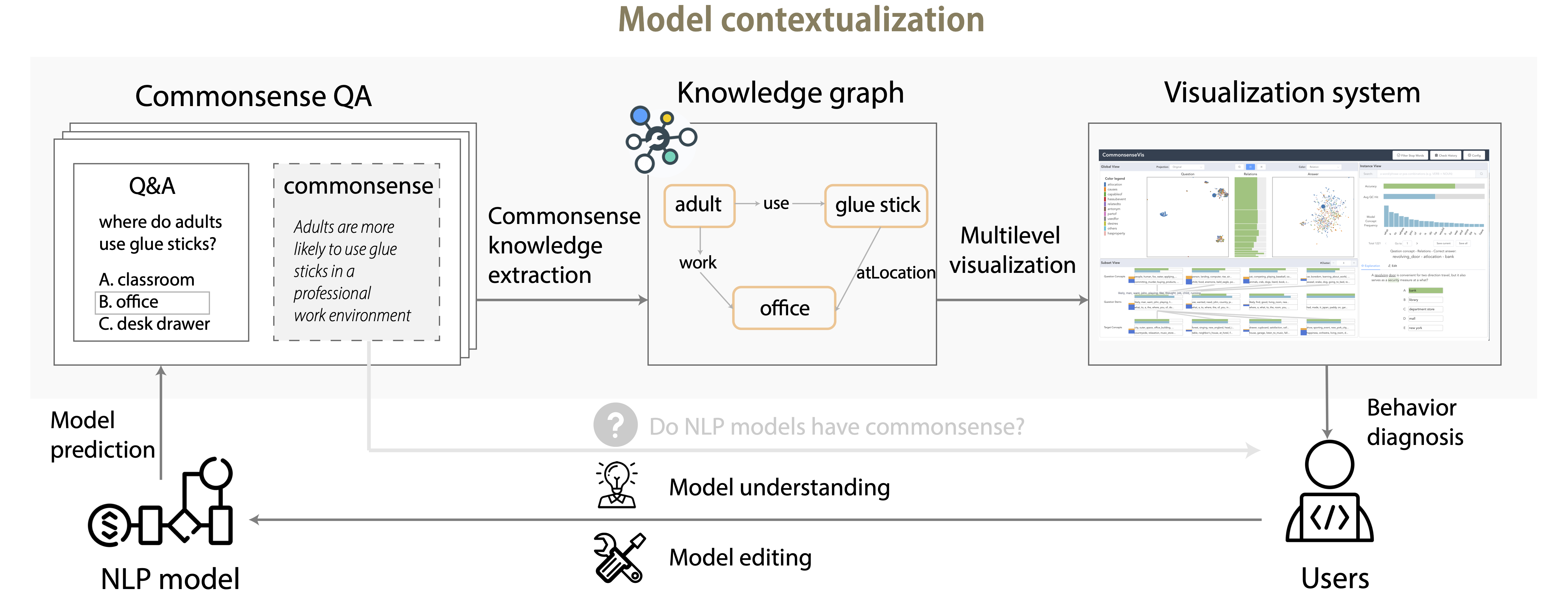
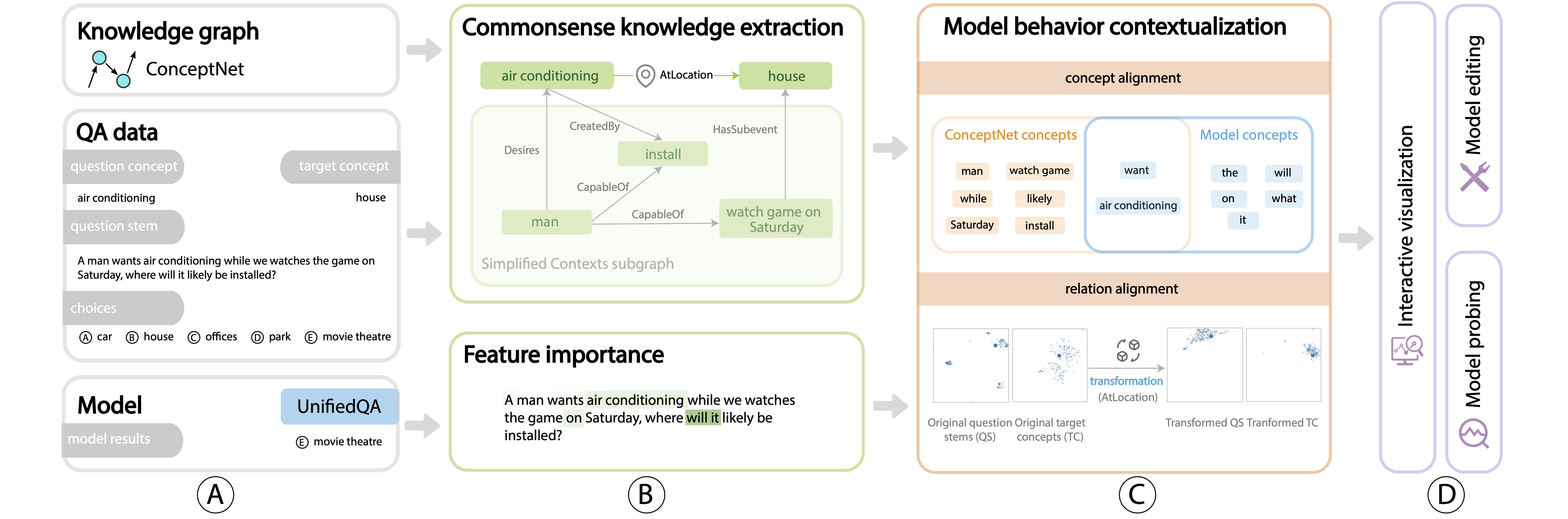
System framework and workflow
(A) First, the QA data, NLP model, and knowledge graph are input into the system. (B) Then our system extracts commonsense knowledge in data input based on ConceptNet, and calculates the feature importance scores for individual words in questions. (C) We then align model behavior with ConceptNet knowledge regarding various concepts and underlying relations. (D) Finally, the results are integrated into the interactive visualization system with extended support of model probing and model editing.
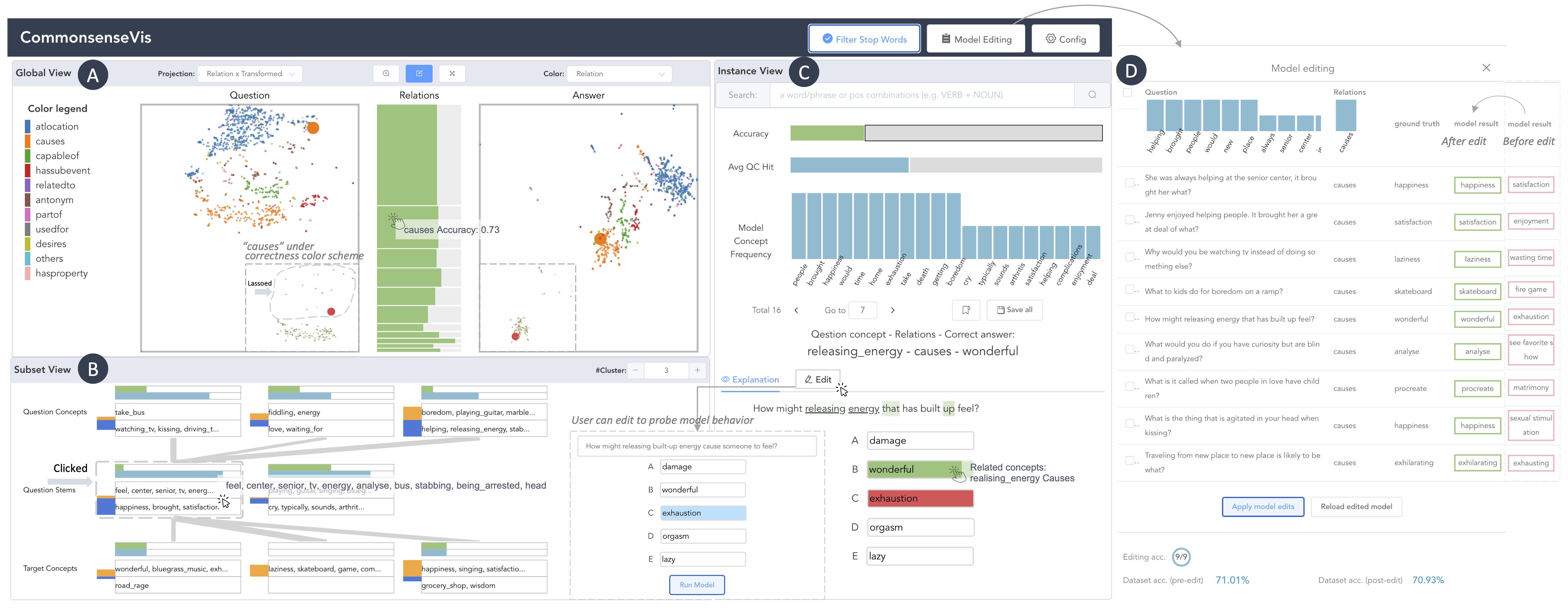
User interface
The user interface enables a multi-level exploration of model behavior following an overview-to-detail flow, contextualized by ConceptNet. The exploration process starts with the Global View, which summarizes model performance on different concepts and relations and assesses overall relation learning. Users then can pinpoint error cases, and the system summarizes the contexts of alignment between model behavior and ConceptNet on different subsets. Upon selecting instance subsets in the Global View or Subset View, Instance View shows statistics and visual explanations for these instances. It facilitates interactive model probing for comprehensive understanding and enables users to bookmark particular instances for targeted model refinement. The system uses red to encode the model error, green to indicate accuracy, categorical colors to encode different relations and statistics.
After identifying model deficits in specific commonsense knowledge, we present editor networks (i.e., neural networks) trained by MEND technique to modify model parameters that can correct problematic model answers ("reliability"), as well as other semantically-equivalent questions ("generality") without affecting unrelated knowledge much after the edit ("locality").
CommonsenseVIS demo
Check out the following video for a quick look at CommonsenseVIS's features.
- System framework (0:00 - 1:31)
- Step I: extract relevant commonsense knowledge (0:14 - 0:49)
- Step II: align model behavior with ConceptNet knowledge (0:49 - 1:23)
- Step III: faciliate exploration via multi-level visualization system (1:23 - 1:31)
- System tasks and workflow (1:31 - 2:24)
- CommonsenseVIS system designs (2:24 - 3:28)
- A use case (3:28 - 6:08)
Conclusion
We presented CommonsenseVIS to help NLP experts to conduct a systematic and scalable analysis of the commonsense reasoning capabilities of language models. It utilized an external commonsense knowledge base to contextualize and visualize the model behavior on different concepts and underlying relations from different levels of detail. Users can interactively probe and edit the model behavior to improve the model's reasoning abilities in specific knowledge areas.
In the future, we can improve the system designs to handle more complex questions with multiple plausible answers and explanations, often influenced by diverse arguments and opinions. Moreover, we can improve the usability of CommonsenseVIS by displaying prediction scores for answer choices in the Instance View and enhancing our model editing methods for larger-scale editing.
Authors

Xingbo Wang, Renfei Huang, Zhihua Jin, Tianqing Fang and Huamin Qu.
IEEE Transactions on Visualization and Computer Graphics. To Appear. (VIS 2023).
- 🌐 Project Page: https://andy-xingbowang.com/commonsenseVIS
- 📃 Paper: https://andy-xingbowang.com/papers/commonsense_vis2023.pdf
- 🎥 Video: https://youtu.be/DVBvKmuZVFI